What a collision actually means in production
A UUID collision is not a philosophical problem. It is a concrete systems problem.
When two records receive the same identifier, one of the following usually happens:
- a database insert fails because of a unique constraint
- one record overwrites another
- an API returns the wrong object
- an event stream links unrelated actions
- logs become harder to trust during incident analysis
Why the abstract math is not the whole story
The theoretical model assumes a high-quality source of randomness and correct formatting. Real systems break those assumptions more often than people expect. The chance of UUID collision in a well-implemented generator is tiny, but bad entropy, broken seeding, copied VM snapshots, or homegrown libraries can make duplicate values appear far sooner than the formula suggests.
The practical difference between “possible” and “relevant”
For most web apps, internal tools, and SaaS backends, the probability is so low that other failures dominate. Disk errors, race conditions, wrong migrations, and bad retry logic are far more likely to hurt data integrity. UUID math becomes important at very large scale or in security-sensitive systems where even an extreme edge case must be modeled.
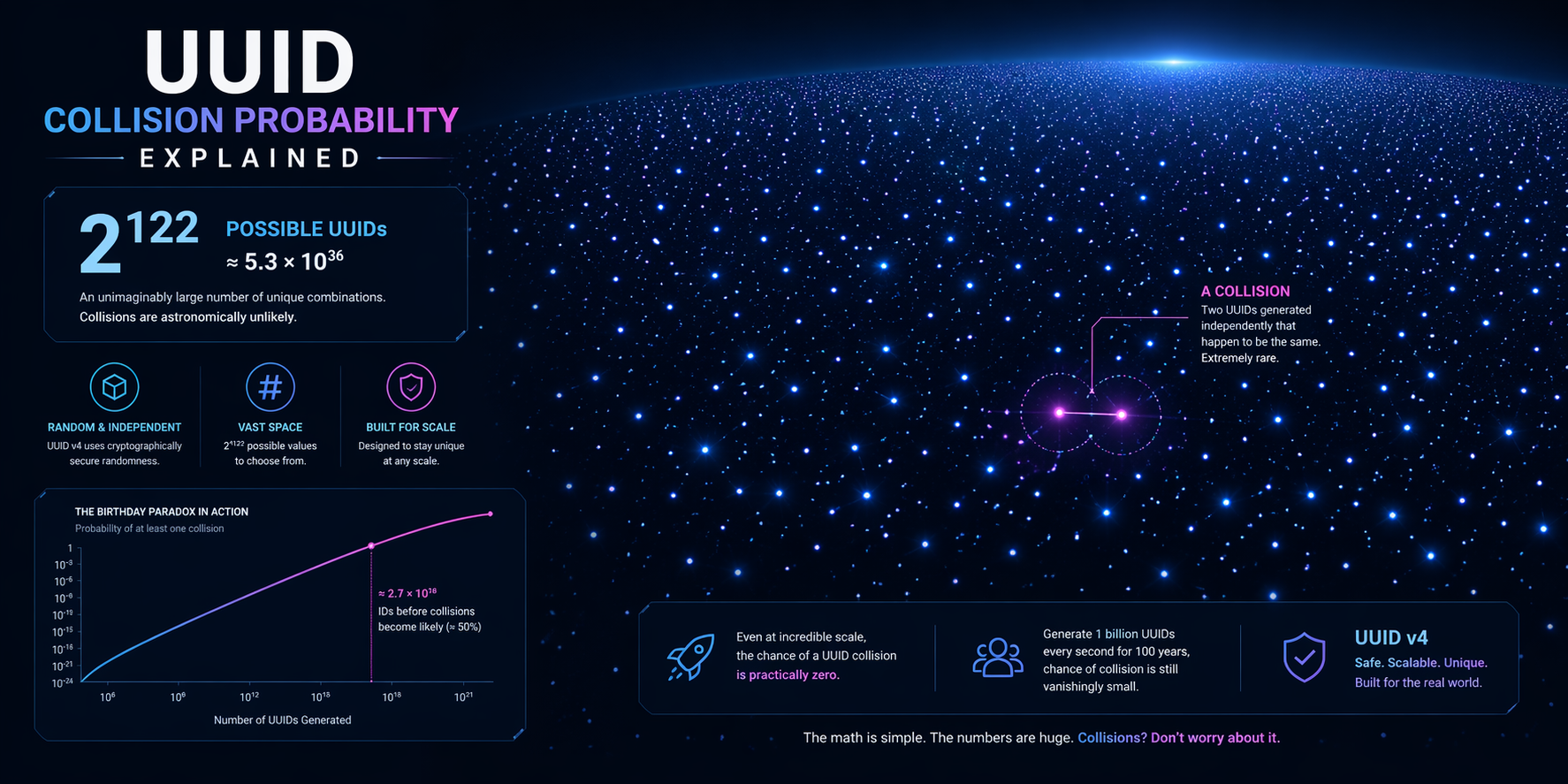
How the probability is estimated
The intuition comes from the birthday paradox. You do not need to exhaust the entire identifier space before duplicates become possible in principle. You only need enough draws for overlap to become statistically noticeable.
The formula engineers actually use
For a random UUID with one hundred twenty-two random bits, collision probability is often approximated as:
P ≈ n² / (2 × 2¹²²)
Where:
- P is the approximate probability of at least one duplicate
- n is the number of generated identifiers
This formula is useful because it shows the real scaling behavior: the risk grows with the square of the sample size. That does not make collisions common. It shows why growth matters more than many teams assume.
Reading the formula correctly
The likelihood of UUID collision remains negligible for ordinary workloads, even when millions or billions of identifiers are created over time. The important lesson is not panic. The lesson is that probability is a moving target tied to volume, generator quality, and system design.
When the odds matter and when they do not
Most teams ask the wrong question. They ask whether a UUID can ever repeat. A better question is whether duplication should be part of the system’s failure model.
Quick reality check
|
Scenario |
Collision concern |
Main reason |
|
Small internal app |
Minimal |
Volume is low and database constraints catch anomalies |
|
Public API with high write throughput |
Low but worth modeling |
Large identifier volume over long periods |
|
Multi-region distributed system |
Moderate operational concern |
Generator quality and environment consistency matter |
|
Security token misuse as UUID |
High design mistake |
Guessability and semantics matter more than duplication |
The odds of a UUID collision are usually not what breaks a system first. Weak assumptions around inserts, retries, and conflict handling break it first.
Example: database insert path
Suppose an order service generates an identifier before writing to storage. A safe design does this:
- generate the identifier with a trusted library
- enforce a unique index in the database
- retry on duplicate-key failure
- log the event for investigation
That pattern treats collisions as improbable but handled, which is exactly the right mindset.
Real sources of UUID problems beyond pure probability
Teams often blame mathematics when the real problem is implementation.
Weak entropy
Containers restored from the same machine image or environments with poor randomness can create repeated output patterns. In that case, the UUID collision risk is no longer driven mainly by the identifier space. It is driven by a broken input source.
Incorrect library usage
A team may truncate identifiers for prettier URLs, remove sections, or convert them through buggy custom code. The result may still look like a UUID while carrying much less entropy than expected.
Wrong identifier for the job
A deterministic name-based UUID can intentionally produce the same value for the same input. That is not a bug. It becomes a bug only when a team expects random behavior from a deterministic scheme.
Common technical situations
Example: bad shortening strategy
A developer takes only the first part of a UUID to make links shorter:
/full-id/abcfde...
/short-id/abcf
That changes the collision surface dramatically. The identifier may still look technical, but its uniqueness guarantees are no longer in the same class.
Example: safe insert logic
INSERT INTO files(id, path, owner)
VALUES (:generated_id, :path, :owner);
This is safe only when id has a unique constraint and the application knows how to retry.
Example: log correlation
Using the same identifier format for tracing across services is fine, but the identifier should not carry business meaning. If a duplicate ever appears, observability must reveal it instead of hiding it.
The question engineers keep asking
The phrase can UUID collide deserves a direct answer: yes, in theory, and sometimes in practice. But with high-quality random generation, the event is so rare that operational mistakes dominate the real-world danger.
Have duplicates ever appeared?
The question have there ever been UUID collisions is often asked as if it disproves the model. It does not. Reported duplicates usually come from flawed generators, low-entropy environments, truncation, copy-paste mistakes, or misuse of deterministic variants. The lesson is simple: most “UUID failures” are engineering failures, not failures of the underlying concept.
How to reduce exposure without overengineering
Use a short checklist
- use a standard library from the platform runtime
- keep full identifiers intact
- enforce uniqueness at the storage layer
- add retry logic on duplicate insert errors
- avoid using UUIDs as secrets or authorization tokens
- test generator behavior in containers, workers, and restored snapshots
What to monitor
The UUID collision rate should not be treated as a normal business metric that you expect to climb. It should be an anomaly signal. If duplicates start appearing, investigate entropy, deployment images, random seeding, and any custom transformation code before blaming probability.
Final takeaway
Random UUIDs are not magic. They are a very strong engineering tool whose safety comes from an enormous space plus correct implementation. For most systems, the collision question is mathematically interesting but operationally minor. For large-scale or sensitive systems, the right approach is not fear. It is disciplined design: trusted generation, database constraints, retries, and observability.
If your system handles duplicates gracefully, UUIDs remain one of the most practical ways to assign identifiers without central coordination. That is the real answer behind modern search intent: use them confidently, but never blindly.