Ce que signifie réellement une collision en production
Une collision d’UUID n’est pas un problème philosophique. C’est un problème système concret.
Lorsque deux enregistrements reçoivent le même identifiant, l’une des situations suivantes se produit généralement :
- une insertion en base de données échoue en raison d’une contrainte d’unicité
- un enregistrement écrase un autre
- une API renvoie le mauvais objet
- un flux d’événements relie des actions sans rapport
- les journaux deviennent plus difficiles à exploiter lors de l’analyse d’incidents
Pourquoi les mathématiques abstraites ne racontent pas toute l’histoire
Le modèle théorique suppose une source d’aléatoire de haute qualité et un formatage correct. Les systèmes réels enfreignent ces hypothèses plus souvent que prévu. La probabilité de collision d’UUID dans un générateur bien implémenté est infime, mais une mauvaise entropie, une initialisation défectueuse, des instantanés de VM copiés ou des bibliothèques maison peuvent faire apparaître des valeurs en double bien plus tôt que ne le suggère la formule.
La différence pratique entre « possible » et « pertinent »
Pour la plupart des applications web, des outils internes et des backends SaaS, la probabilité est si faible que d’autres défaillances dominent. Les erreurs disque, les conditions de course, les mauvaises migrations et une logique de réessai défaillante sont bien plus susceptibles d’affecter l’intégrité des données. Les mathématiques des UUID deviennent importantes à très grande échelle ou dans les systèmes sensibles à la sécurité où même un cas extrême doit être modélisé.
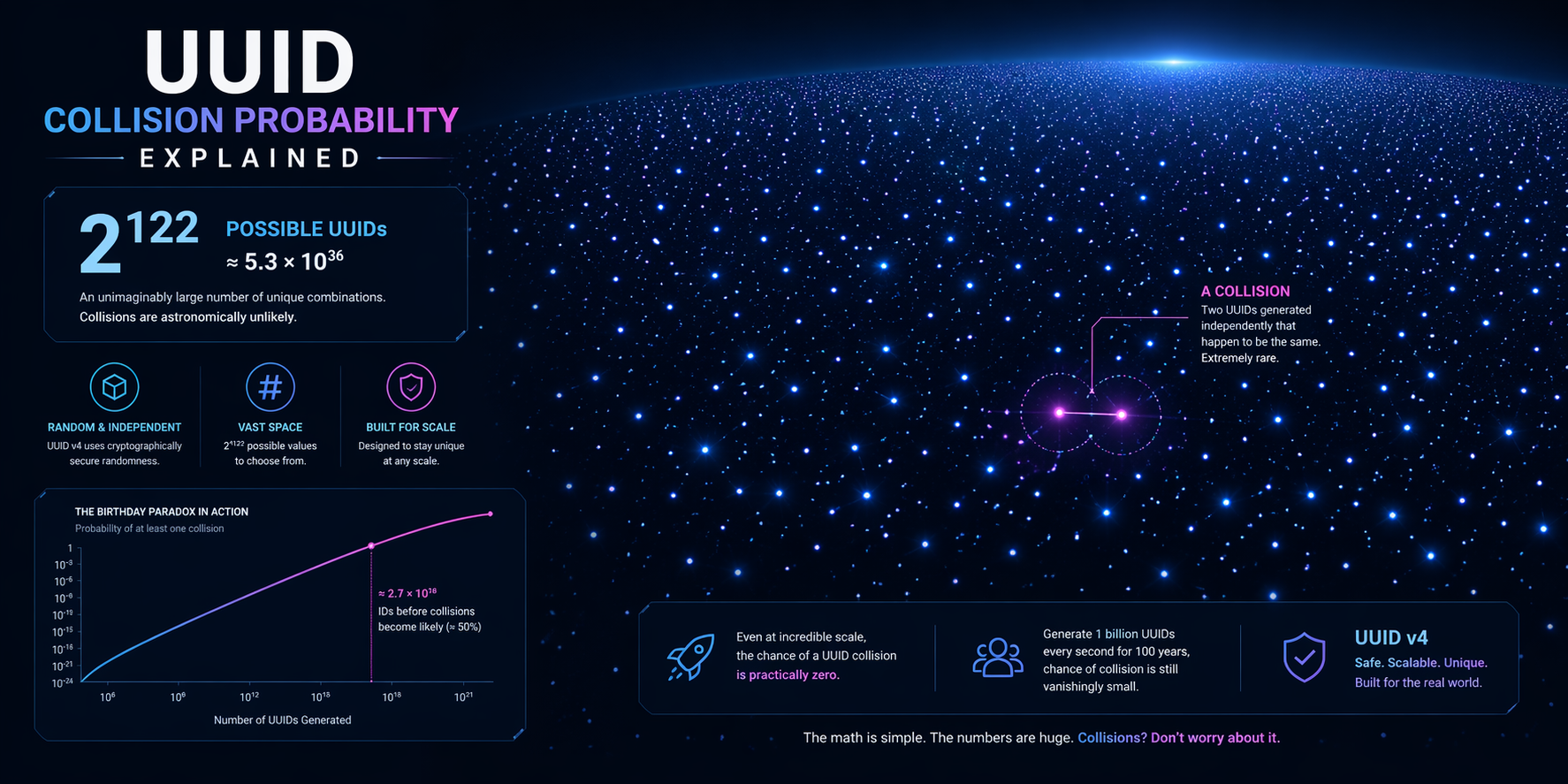
Comment la probabilité est estimée
L’intuition vient du paradoxe des anniversaires. Il n’est pas nécessaire d’épuiser tout l’espace d’identifiants avant que les doublons soient possibles en principe. Il suffit d’un nombre suffisant de tirages pour que le chevauchement devienne statistiquement perceptible.
La formule que les ingénieurs utilisent vraiment
Pour un UUID aléatoire avec cent vingt-deux bits aléatoires, la probabilité de collision est souvent approchée par :
P ≈ n² / (2 × 2¹²²)
Où :
- P est la probabilité approximative d’au moins un doublon
- n est le nombre d’identifiants générés
Cette formule est utile car elle montre le comportement réel à l’échelle : le risque croît avec le carré de la taille de l’échantillon. Cela ne rend pas les collisions courantes. Cela montre pourquoi la croissance est plus importante que beaucoup d’équipes ne le supposent.
Lire la formule correctement
La probabilité de collision d’UUID reste négligeable pour les charges de travail ordinaires, même lorsque des millions ou des milliards d’identifiants sont créés au fil du temps. La leçon importante n’est pas la panique. La leçon est que la probabilité est une cible mouvante liée au volume, à la qualité du générateur et à la conception du système.
Quand les probabilités importent et quand elles n’importent pas
La plupart des équipes posent la mauvaise question. Elles demandent si un UUID peut jamais se répéter. Une meilleure question est de savoir si la duplication doit faire partie du modèle de défaillance du système.
Vérification rapide de la réalité
|
Scénario |
Préoccupation de collision |
Raison principale |
|
Petite application interne |
Minimale |
Le volume est faible et les contraintes de base de données capturent les anomalies |
|
API publique à fort débit d’écriture |
Faible mais vaut la peine d’être modélisée |
Grand volume d’identifiants sur de longues périodes |
|
Système distribué multi-région |
Préoccupation opérationnelle modérée |
La qualité du générateur et la cohérence de l’environnement importent |
|
Token de sécurité mal utilisé comme UUID |
Haute – erreur de conception |
La devinabilité et la sémantique importent plus que la duplication |
Les probabilités de collision d’UUID ne sont généralement pas ce qui brise un système en premier. Les hypothèses faibles autour des insertions, des réessais et de la gestion des conflits le brisent en premier.
Exemple : chemin d’insertion en base de données
Supposons qu’un service de commandes génère un identifiant avant d’écrire dans le stockage. Une conception sûre fait ceci :
- générer l’identifiant avec une bibliothèque de confiance
- imposer un index unique dans la base de données
- réessayer en cas d’échec de clé dupliquée
- journaliser l’événement pour investigation
Ce modèle traite les collisions comme improbables mais gérées, ce qui est exactement la bonne mentalité.
Sources réelles de problèmes UUID au-delà de la probabilité pure
Les équipes reprochent souvent aux mathématiques ce dont le vrai problème est l’implémentation.
Entropie faible
Les conteneurs restaurés à partir de la même image machine ou les environnements avec peu d’aléatoire peuvent créer des modèles de sortie répétés. Dans ce cas, le risque de collision UUID n’est plus principalement piloté par l’espace d’identifiants. Il est piloté par une source d’entrée défectueuse.
Utilisation incorrecte de bibliothèque
Une équipe peut tronquer les identifiants pour des URL plus jolies, supprimer des sections ou les convertir via du code personnalisé bogus. Le résultat peut toujours ressembler à un UUID tout en portant beaucoup moins d’entropie que prévu.
Mauvais identifiant pour la tâche
Un UUID déterministe basé sur le nom peut intentionnellement produire la même valeur pour la même entrée. Ce n’est pas un bogue. Cela devient un bogue uniquement lorsqu’une équipe attend un comportement aléatoire d’un schéma déterministe.
Situations techniques courantes
Exemple : mauvaise stratégie de raccourcissement
Un développeur ne prend que la première partie d’un UUID pour raccourcir les liens :
/full-id/abcfde...
/short-id/abcf
Cela modifie considérablement la surface de collision. L’identifiant peut toujours sembler technique, mais ses garanties d’unicité ne sont plus dans la même classe.
Exemple : logique d’insertion sécurisée
INSERT INTO files(id, path, owner)
VALUES (:generated_id, :path, :owner);
Ceci est sûr uniquement lorsque id a une contrainte d’unicité et que l’application sait comment réessayer.
Exemple : corrélation des journaux
Utiliser le même format d’identifiant pour le traçage entre services est correct, mais l’identifiant ne doit pas avoir de signification métier. Si un doublon apparaît, l’observabilité doit le révéler plutôt que le cacher.
La question que les ingénieurs continuent de poser
La phrase « un UUID peut-il entrer en collision » mérite une réponse directe : oui, en théorie, et parfois en pratique. Mais avec une génération aléatoire de haute qualité, l’événement est si rare que les erreurs opérationnelles dominent le danger réel.
Des doublons sont-ils jamais apparus ?
La question « y a-t-il jamais eu des collisions d’UUID » est souvent posée comme si elle réfutait le modèle. Ce n’est pas le cas. Les doublons signalés proviennent généralement de générateurs défectueux, d’environnements à faible entropie, de troncature, d’erreurs de copier-coller ou d’une mauvaise utilisation des variantes déterministes. La leçon est simple : la plupart des « échecs UUID » sont des échecs d’ingénierie, pas des échecs du concept sous-jacent.
Comment réduire l’exposition sans sur-ingénierie
Utiliser une courte liste de contrôle
- utiliser une bibliothèque standard de l’environnement d’exécution de la plateforme
- conserver les identifiants complets intacts
- imposer l’unicité au niveau de la couche de stockage
- ajouter une logique de réessai sur les erreurs d’insertion dupliquée
- ne pas utiliser les UUID comme secrets ou tokens d’autorisation
- tester le comportement du générateur dans les conteneurs, les workers et les instantanés restaurés
Que surveiller
Le taux de collision UUID ne doit pas être traité comme une métrique métier normale que l’on s’attend à voir augmenter. Ce doit être un signal d’anomalie. Si des doublons commencent à apparaître, investiguer l’entropie, les images de déploiement, l’initialisation aléatoire et tout code de transformation personnalisé avant d’incriminer la probabilité.
Conclusion
Les UUID aléatoires ne sont pas magiques. Ce sont des outils d’ingénierie très solides dont la sécurité provient d’un espace énorme combiné à une implémentation correcte. Pour la plupart des systèmes, la question de la collision est mathématiquement intéressante mais opérationnellement mineure. Pour les systèmes à grande échelle ou sensibles, la bonne approche n’est pas la peur. C’est une conception disciplinée : génération de confiance, contraintes de base de données, réessais et observabilité.
Si votre système gère les doublons correctement, les UUID restent l’un des moyens les plus pratiques d’attribuer des identifiants sans coordination centrale. C’est la vraie réponse : utilisez-les avec confiance, mais jamais aveuglément.