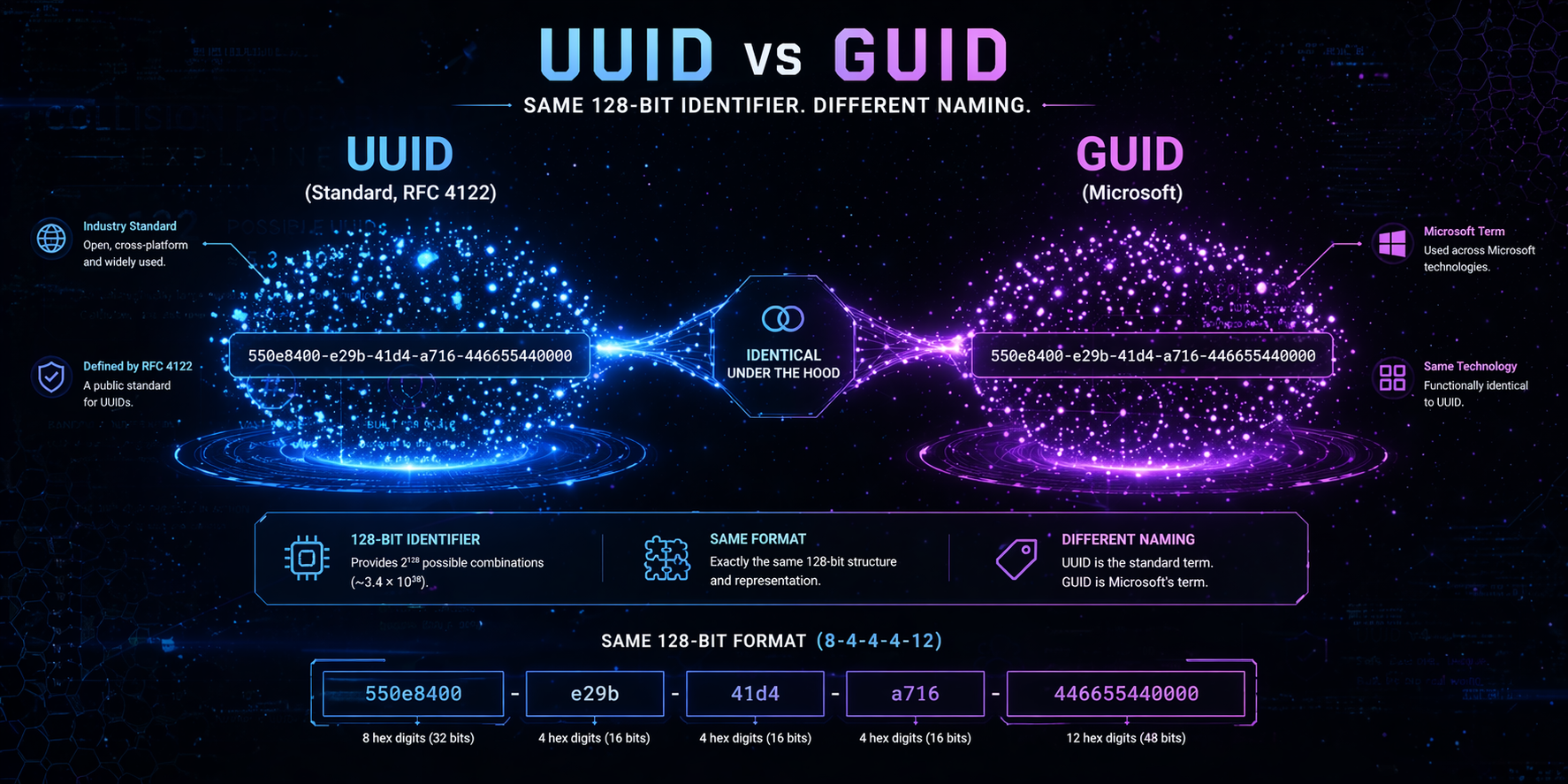
GUID vs UUID : terminologie et contexte historique
Ces termes proviennent d'écosystèmes différents.
- L'UUID (Universally Unique Identifier) est défini par des normes internationales telles que RFC 4122 et ISO/IEC 9834-8.
- GUID (Globally Unique Identifier) est le nom utilisé par Microsoft pour désigner le même format d'identifiant 128 bits dans Windows, COM et .NET.
La norme RFC 4122 stipule explicitement que les UUID sont également appelés GUID. La documentation Microsoft confirme que ses identifiants suivent la même structure et les mêmes règles de génération.
Du point de vue des normes, il n'y a pas de divergence structurelle : la différence réside dans la convention de nommage et le contexte de l'écosystème.
UUID et GUID : structure interne et format
Ces deux identifiants partagent des caractéristiques fondamentales identiques :
- 128 bits (16 octets)
- Représentés par 32 chiffres hexadécimaux
- Format textuel commun : 8-4-4-4-12
Exemple :
550e8400-e29b-41d4-a716-446655440000
Champs structurels
Un identifiant normalisé comprend :
- Composante temporelle ou aléatoire
- Champ de version
- Champ de variante
- Nœud supplémentaire ou bits aléatoires
Le champ de version détermine la manière dont la valeur a été générée.
Le champ de variante détermine la compatibilité avec la famille de spécifications.
Ces éléments existent indépendamment de la terminologie.
Différence entre GUID et UUID au niveau des spécifications
Pour évaluer la différence entre GUID et UUID, nous devons examiner l'alignement des spécifications.
La RFC 4122 définit :
- La disposition des bits
- La numérotation des versions
- Le codage des variantes
- La représentation textuelle canonique
La mise en œuvre de Microsoft s'aligne sur ces règles. Les anciens systèmes Windows incluaient des variantes de compatibilité, mais la génération moderne de GUID est conforme aux exigences de la RFC.
Versions définies par la RFC 4122
|
Version |
Méthode de génération |
Utilisation type |
|
1 |
Horodatage + MAC |
Systèmes hérités |
|
2 |
Sécurité DCE |
Rare |
|
3 |
Basé sur le nom (MD5) |
Identifiants déterministes |
|
4 |
Aléatoire |
Le plus courant |
|
5 |
Basé sur le nom (SHA-1) |
Déterministe (hachage plus puissant |
Dans les logiciels modernes, la version 4 domine en raison de sa simplicité et de son caractère fortement aléatoire.
Il n'existe pas de version exclusive à un seul terme.
GUID ou UUID : différences pratiques en programmation
Dans le développement d'applications, la distinction n'apparaît généralement que dans la dénomination des API.
.NET
Guid id=Guid.NewGuid();
Java
UUID id=UUID.randomUUID();
Python
import uuid
uuid.uuid4()
Go
import « github.com/google/uuid »
id := uuid.New()
Tous les exemples produisent des identifiants de version 4 conformes à la norme RFC.
La différence réside dans le nom du type, et non dans la structure ou la logique de génération.
Ordre des octets et représentation binaire
La nuance la plus technique apparaît au niveau binaire.
La RFC définit les champs dans l'ordre des octets réseau (big-endian).
Windows stockait historiquement certains composants en interne en utilisant un endiannage mixte.
Cela affecte :
- Les comparaisons d'octets bruts
- La sérialisation binaire
- L'échange binaire entre plateformes
Important :
La forme textuelle canonique reste identique sur toutes les plateformes.
Recommandation pratique
Lorsque l'interopérabilité est importante :
- Échangez les identifiants sous forme de chaînes de caractères.
- Évitez la comparaison directe d'octets bruts entre les systèmes.
- Utilisez des bibliothèques d'analyse officielles.
Comparaison structurelle
|
Aspect |
UUID (terme standard) |
GUID (terme Microsoft) |
|
Longueur |
128 bits |
128 bits |
|
Spécification applicable |
RFC 4122 |
Implémentation basée sur RFC |
|
Format texte |
8-4-4-4-12 hex |
Identique |
|
Version courante |
v4 |
v4 |
|
Multiplateforme |
Oui |
Oui |
|
Origine de l'écosystème |
IETF / ISO |
Microsoft |
Le tableau montre une équivalence pratique.
Quand la distinction a réellement de l'importance
Dans les scénarios classiques (API REST, microservices, bases de données), il n'y a aucune différence de comportement.
Cependant, la prudence est de mise dans les cas suivants :
- Interopérabilité COM
- RPC Windows hérité
- Stockage binaire de bas niveau
- Hachage au niveau des octets ou signature numérique
- Formats de sérialisation personnalisés
Si les identifiants sont traités uniquement comme des tableaux de 16 octets, l'endianness doit être gérée explicitement.
Sécurité et meilleures pratiques
Les caractéristiques de sécurité dépendent de la version, et non de la terminologie.
- La version 1 peut exposer les informations relatives à l'horodatage et au matériel.
- La version 4 est recommandée pour les identifiants uniques à usage général.
- Les versions 3 et 5 fournissent des valeurs déterministes basées sur les noms.
Meilleures pratiques :
- Utilisez toujours des bibliothèques standard.
- Préférez la version 4, sauf si un comportement déterministe est requis.
- Stockez dans un format textuel canonique pour plus de portabilité.
- Évitez de construire manuellement des séquences aléatoires de 16 octets : les bits de version et de variante doivent être correctement définis.
Précision finale
Dans l'ingénierie logicielle moderne, les deux termes font référence à la même norme d'identifiant unique de 128 bits.
La distinction est historique et déterminée par l'écosystème :
- l'un des termes trouve son origine dans des spécifications internationales formelles.
- L'autre trouve son origine dans la nomenclature de mise en œuvre de Microsoft.
D'un point de vue fonctionnel, structurel et algorithmique, ils décrivent le même format d'identifiant. Comprendre cela élimine toute confusion inutile et permet de se concentrer sur les considérations techniques réelles : méthode de génération, sérialisation, stratégie de stockage et interopérabilité.