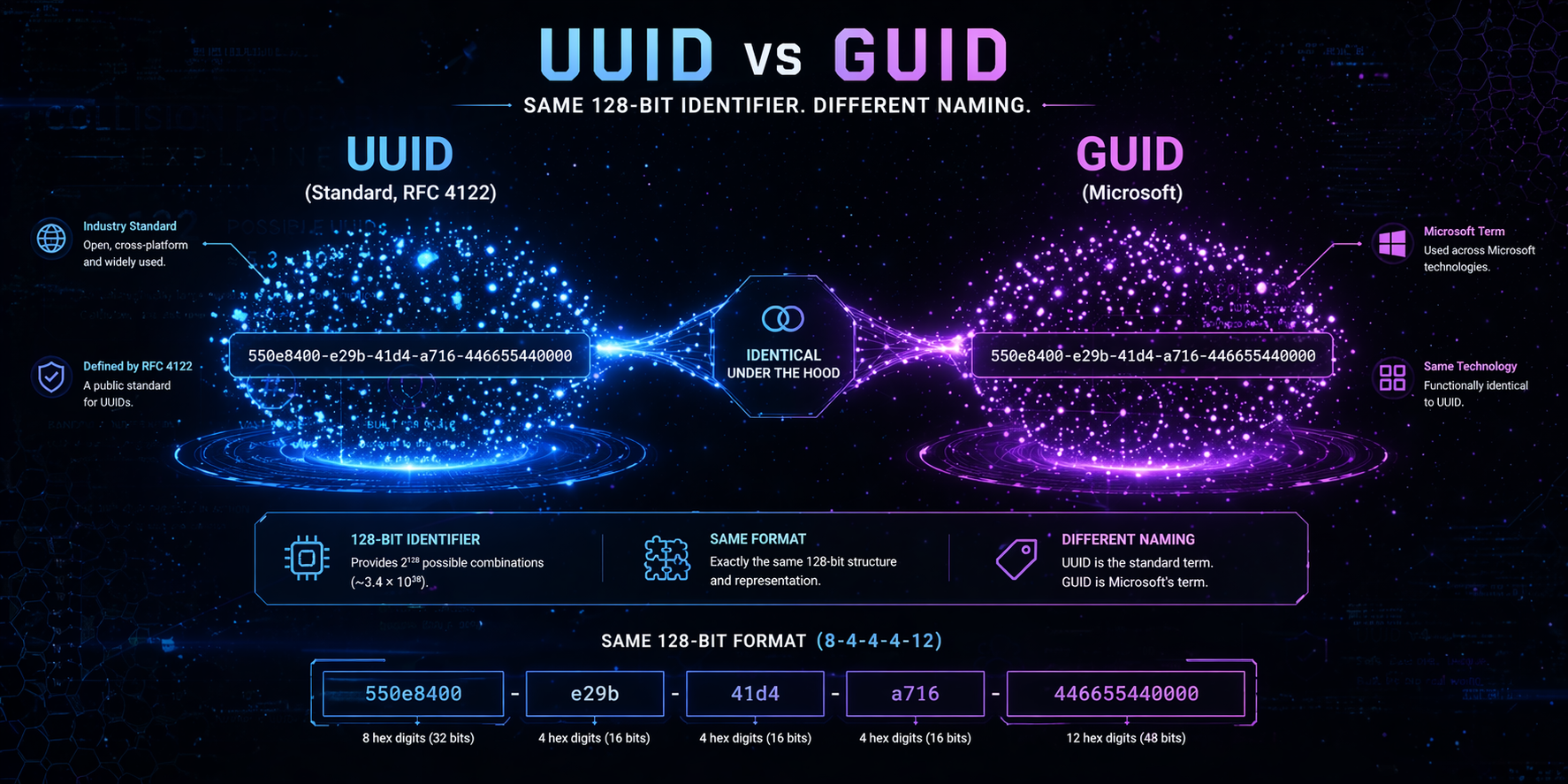
GUID vs. UUID: Terminologie und historischer Hintergrund
Die Begriffe stammen aus unterschiedlichen Ökosystemen.
- UUID (Universally Unique Identifier) ist durch internationale Standards wie RFC 4122 und ISO/IEC 9834-8 definiert.
- GUID (Globally Unique Identifier) ist die Bezeichnung, die Microsoft für dasselbe 128-Bit-Identifikatorformat in Windows, COM und .NET verwendet.
RFC 4122 legt ausdrücklich fest, dass UUIDs auch als GUIDs bezeichnet werden. Die Dokumentation von Microsoft bestätigt, dass seine Identifikatoren derselben Struktur und denselben Generierungsregeln folgen.
Aus Sicht der Standards gibt es keine strukturellen Unterschiede – der Unterschied liegt in der Namenskonvention und dem Kontext des Ökosystems.
UUID und GUID: Interne Struktur und Format
Beide Identifikatoren weisen identische Kernmerkmale auf:
- 128 Bit (16 Byte)
- Darstellung als 32 Hexadezimalziffern
- Gängiges Textformat: 8-4-4-4-12
Beispiel:
550e8400-e29b-41d4-a716-446655440000
Strukturelle Felder
Ein standardisierter Identifikator umfasst:
- Zeitbasierte oder zufällige Komponente
- Versionsfeld
- Variantenfeld
- Zusätzliche Knoten- oder Zufallsbits
Das Versionsfeld bestimmt, wie der Wert generiert wurde.
Das Variantenfeld bestimmt die Kompatibilität mit der Spezifikationsfamilie.
Diese Elemente existieren unabhängig von der Terminologie.
Unterschied zwischen GUID und UUID auf Spezifikationsebene
Um den Unterschied zwischen GUID und UUID zu bewerten, müssen wir die Spezifikationsangleichung untersuchen.
RFC 4122 definiert:
- Bit-Layout
- Versionsnummerierung
- Variantenkodierung
- Kanonische Textdarstellung
Die Implementierung von Microsoft entspricht diesen Regeln. Frühere Windows-Systeme enthielten Kompatibilitätsvarianten, aber die moderne GUID-Generierung entspricht den RFC-Anforderungen.
Durch RFC 4122 definierte Versionen
|
Version |
Erzeugungsmethode |
Typical Usage |
|
1 |
Zeitstempel + MAC |
Altsysteme |
|
2 |
DCE-Sicherheit |
Selten |
|
3 |
Namensbasiert (MD5) |
Deterministische IDs |
|
4 |
Zufällig |
Am häufigsten |
|
5 |
Namensbasiert (SHA-1) |
Deterministisch (stärkerer Hash) |
In moderner Software dominiert Version 4 aufgrund ihrer Einfachheit und starken Zufälligkeit.
Es gibt keine Version, die ausschließlich für einen Begriff gilt.
GUID oder UUID: Praktische Unterschiede in der Programmierung
In der Anwendungsentwicklung zeigt sich der Unterschied in der Regel nur in der Benennung der APIs.
.NET
Guid id=Guid.NewGuid();
Java
UUID id=UUID.randomUUID();
Python
import uuid
uuid.uuid4()
Go
import „github.com/google/uuid“
id := uuid.New()
Alle Beispiele erzeugen RFC-konforme Identifikatoren der Version 4.
Der Unterschied liegt im Typnamen, nicht in der Struktur oder der Generierungslogik.
Byte-Reihenfolge und binäre Darstellung
Die technischste Nuance tritt auf der binären Ebene auf.
RFC definiert Felder in Netzwerk-Byte-Reihenfolge (Big-Endian).
Windows hat bestimmte Komponenten intern historisch mit gemischter Endianness gespeichert.
Dies wirkt sich aus auf:
- Rohbytevergleiche
- Binäre Serialisierung
- Plattformübergreifenden Binärdatenaustausch
Wichtig:
Die kanonische Textform bleibt plattformübergreifend identisch.
Praktische Empfehlung
Wenn Interoperabilität wichtig ist:
- Tauschen Sie Identifikatoren als Zeichenfolgen aus.
- Vermeiden Sie direkte Rohbytevergleiche zwischen Systemen.
- Verwenden Sie offizielle Parsing-Bibliotheken.
Struktureller Vergleich
|
Aspekt |
UUID (Standardbegriff) |
GUID (Microsoft-Begriff) |
|
Länge |
128 Bit |
128 Bit |
|
Geltende Spezifikation |
RFC 4122 |
RFC-basierte Implementierung |
|
Textformat |
8-4-4-4-12 hex |
Gleich |
|
Allgemeine Version |
v4 |
v4 |
|
Plattformübergreifend |
Ja |
Ja |
|
Entstehung des Ökosystems |
IETF / ISO |
Microsoft |
Die Tabelle zeigt die praktische Äquivalenz.
Wann die Unterscheidung tatsächlich von Bedeutung ist
In typischen Szenarien – REST-APIs, Microservices, Datenbanken – gibt es keinen Unterschied im Verhalten.
Vorsicht ist jedoch geboten bei:
- COM-Interoperabilität
- Legacy-Windows-RPC
- Low-Level-Binärspeicherung
- Hashing auf Byte-Ebene oder digitale Signatur
- Benutzerdefinierte Serialisierungsformate
Wenn Identifikatoren rein als 16-Byte-Arrays behandelt werden, muss die Endianness explizit behandelt werden.
Sicherheit und bewährte Verfahren
Die Sicherheitsmerkmale hängen von der Version ab, nicht von der Terminologie.
- Version 1 kann Zeitstempel- und Hardwareinformationen offenlegen.
- Version 4 wird für allgemeine eindeutige Identifikatoren empfohlen.
- Die Versionen 3 und 5 liefern deterministische Werte auf der Grundlage von Namen.
Bewährte Verfahren:
- Verwenden Sie immer Standardbibliotheken.
- Verwenden Sie vorzugsweise Version 4, es sei denn, deterministisches Verhalten ist erforderlich.
- Speichern Sie die Daten im kanonischen Textformat, um die Portabilität zu gewährleisten.
- Vermeiden Sie die manuelle Erstellung zufälliger 16-Byte-Sequenzen – Versions- und Variantenbits müssen korrekt gesetzt sein.
Abschließende Klarstellung
In der modernen Softwareentwicklung beziehen sich beide Begriffe auf denselben 128-Bit-Standard für eindeutige Identifikatoren.
Die Unterscheidung ist historisch bedingt und ergibt sich aus dem Ökosystem:
- Der eine Begriff stammt aus formalen internationalen Spezifikationen.
- Der andere stammt aus der Namensgebung von Microsoft für die Implementierung.
Funktional, strukturell und algorithmisch beschreiben sie dasselbe Identifikatorformat. Dieses Verständnis beseitigt unnötige Verwirrung und lenkt den Fokus auf die eigentlichen technischen Überlegungen: Generierungsmethode, Serialisierung, Speicherstrategie und Interoperabilität.