Was eine Kollision in der Produktion tatsächlich bedeutet
Eine UUID-Kollision ist kein philosophisches Problem. Sie ist ein konkretes Systemproblem.
Wenn zwei Datensätze denselben Bezeichner erhalten, passiert in der Regel eines der folgenden Dinge:
- ein Datenbank-Insert schlägt aufgrund einer Unique-Constraint-Verletzung fehl
- ein Datensatz überschreibt einen anderen
- eine API gibt das falsche Objekt zurück
- ein Ereignisstrom verknüpft nicht zusammenhängende Aktionen
- Logs werden während der Vorfallsanalyse schwerer nachvollziehbar
Warum die abstrakte Mathematik nicht die ganze Geschichte ist
Das theoretische Modell setzt eine hochwertige Zufallsquelle und korrekte Formatierung voraus. Reale Systeme verletzen diese Annahmen häufiger als erwartet. Die Wahrscheinlichkeit einer UUID-Kollision bei einem gut implementierten Generator ist winzig, aber schlechte Entropie, fehlerhafte Initialisierung, kopierte VM-Snapshots oder selbst entwickelte Bibliotheken können dazu führen, dass doppelte Werte deutlich früher auftreten als die Formel vermuten lässt.
Der praktische Unterschied zwischen "möglich" und "relevant"
Für die meisten Web-Apps, internen Tools und SaaS-Backends ist die Wahrscheinlichkeit so gering, dass andere Fehler überwiegen. Festplattenfehler, Race Conditions, fehlerhafte Migrationen und schlechte Retry-Logik gefährden die Datenintegrität weit häufiger. Die UUID-Mathematik wird bei sehr großem Maßstab oder in sicherheitskritischen Systemen wichtig, bei denen selbst extreme Grenzfälle modelliert werden müssen.
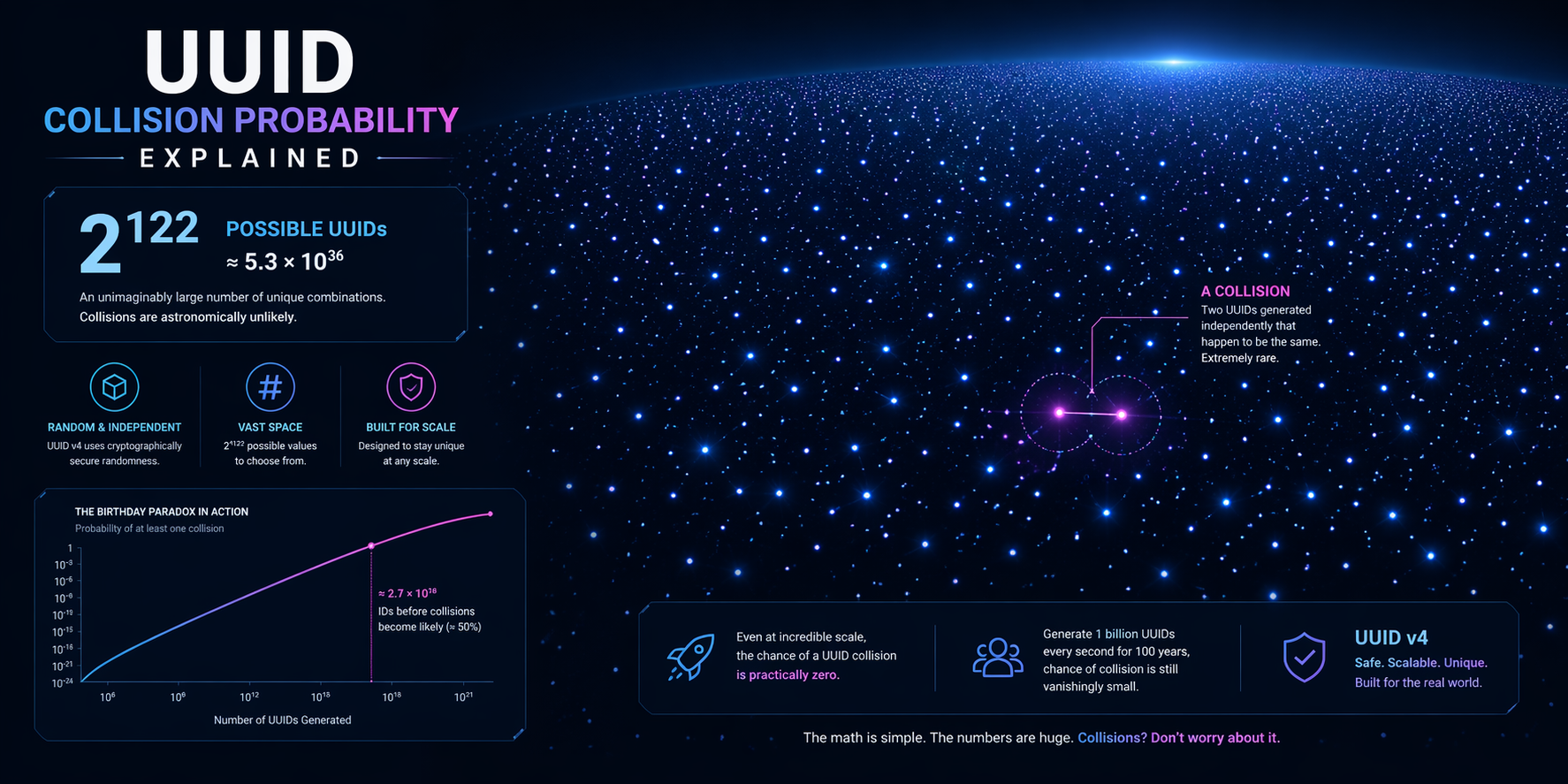
Wie die Wahrscheinlichkeit geschätzt wird
Die Intuition stammt aus dem Geburtstagsparadoxon. Man muss nicht den gesamten Bezeichnerraum erschöpfen, bevor Duplikate prinzipiell möglich werden. Man benötigt nur genug Ziehungen, damit Überschneidungen statistisch merklich werden.
Die Formel, die Entwickler tatsächlich verwenden
Für eine zufällige UUID mit 122 zufälligen Bits wird die Kollisionswahrscheinlichkeit oft wie folgt näherungsweise berechnet:
P ≈ n² / (2 × 2¹²²)
Dabei gilt:
- P ist die ungefähre Wahrscheinlichkeit mindestens eines Duplikats
- n ist die Anzahl der generierten Bezeichner
Diese Formel ist nützlich, weil sie das tatsächliche Skalierungsverhalten zeigt: Das Risiko wächst mit dem Quadrat der Stichprobengröße. Das macht Kollisionen nicht häufig. Es zeigt, warum Wachstum wichtiger ist, als viele Teams annehmen.
Die Formel richtig lesen
Die Wahrscheinlichkeit einer UUID-Kollision bleibt bei normalen Arbeitslasten vernachlässigbar, selbst wenn im Laufe der Zeit Millionen oder Milliarden von Bezeichnern erstellt werden. Die wichtige Lektion ist nicht Panik. Die Lektion ist, dass Wahrscheinlichkeit ein bewegliches Ziel ist, das mit Volumen, Generator-Qualität und Systemdesign zusammenhängt.
Wann die Wahrscheinlichkeiten wichtig sind und wann nicht
Die meisten Teams stellen die falsche Frage. Sie fragen, ob eine UUID jemals wiederholt werden kann. Eine bessere Frage ist, ob Duplikate Teil des Fehlermodells des Systems sein sollten.
Schnelle Realitätsprüfung
|
Szenario |
Kollisionsbedenken |
Hauptgrund |
|
Kleine interne App |
Minimal |
Volumen ist gering und Datenbank-Constraints fangen Anomalien ab |
|
Öffentliche API mit hohem Schreibdurchsatz |
Gering, aber modellierwürdig |
Großes Bezeichnervolumen über lange Zeiträume |
|
Verteiltes Multi-Region-System |
Moderates betriebliches Problem |
Generator-Qualität und Umgebungskonsistenz sind wichtig |
|
Sicherheits-Token, der als UUID missbraucht wird |
Hoch – Designfehler |
Ratbarkeit und Semantik sind wichtiger als Duplikate |
Die Wahrscheinlichkeit einer UUID-Kollision bricht ein System normalerweise nicht zuerst. Schwache Annahmen rund um Inserts, Wiederholungsversuche und Konfliktbehandlung brechen es zuerst.
Beispiel: Datenbank-Insert-Pfad
Angenommen, ein Bestellservice generiert einen Bezeichner vor dem Schreiben in den Speicher. Ein sicheres Design tut Folgendes:
- Bezeichner mit einer vertrauenswürdigen Bibliothek generieren
- Unique-Index in der Datenbank erzwingen
- Bei Duplicate-Key-Fehler wiederholen
- Ereignis zur Untersuchung protokollieren
Dieses Muster behandelt Kollisionen als unwahrscheinlich, aber behandelt – genau die richtige Einstellung.
Echte Quellen von UUID-Problemen jenseits der reinen Wahrscheinlichkeit
Teams geben oft der Mathematik die Schuld, wenn das eigentliche Problem die Implementierung ist.
Schwache Entropie
Container, die aus demselben Maschinenabbild wiederhergestellt werden, oder Umgebungen mit schlechter Zufälligkeit können wiederholte Ausgabemuster erzeugen. In diesem Fall wird das Kollisionsrisiko nicht mehr hauptsächlich durch den Bezeichnerraum bestimmt, sondern durch eine defekte Eingabequelle.
Falsche Bibliotheksverwendung
Ein Team kann Bezeichner für hübschere URLs kürzen, Abschnitte entfernen oder sie durch fehlerhaften benutzerdefinierten Code konvertieren. Das Ergebnis kann immer noch wie eine UUID aussehen, enthält aber deutlich weniger Entropie als erwartet.
Falscher Bezeichner für die Aufgabe
Eine deterministische, namensbasierte UUID kann absichtlich denselben Wert für dieselbe Eingabe erzeugen. Das ist kein Bug. Es wird zum Bug, wenn ein Team zufälliges Verhalten von einem deterministischen Schema erwartet.
Häufige technische Situationen
Beispiel: Schlechte Verkürzungsstrategie
Ein Entwickler nimmt nur den ersten Teil einer UUID, um Links kürzer zu machen:
/full-id/abcfde...
/short-id/abcf
Das verändert die Kollisionsfläche dramatisch. Der Bezeichner mag noch technisch aussehen, aber seine Eindeutigkeitsgarantien gehören nicht mehr derselben Klasse an.
Beispiel: Sichere Insert-Logik
INSERT INTO files(id, path, owner)
VALUES (:generated_id, :path, :owner);
Dies ist nur dann sicher, wenn id eine Unique-Constraint hat und die Anwendung weiß, wie sie wiederholen soll.
Beispiel: Log-Korrelation
Die Verwendung desselben Bezeichnerformats für das Tracing über Dienste hinweg ist in Ordnung, aber der Bezeichner sollte keine Geschäftsbedeutung tragen. Wenn jemals ein Duplikat auftaucht, muss die Observability es aufdecken, anstatt es zu verbergen.
Die Frage, die Entwickler immer wieder stellen
Der Ausdruck "Kann eine UUID kollidieren?" verdient eine direkte Antwort: ja, theoretisch, und manchmal in der Praxis. Aber bei hochwertiger zufälliger Generierung ist das Ereignis so selten, dass betriebliche Fehler die eigentliche Weltgefahr dominieren.
Gab es jemals UUID-Kollisionen?
Die Frage wird oft so gestellt, als würde sie das Modell widerlegen. Das tut sie nicht. Gemeldete Duplikate entstehen normalerweise durch fehlerhafte Generatoren, Umgebungen mit geringer Entropie, Kürzung, Copy-Paste-Fehler oder Missbrauch deterministischer Varianten. Die Lektion ist einfach: Die meisten "UUID-Fehler" sind Engineeringfehler, keine Fehler des zugrunde liegenden Konzepts.
So reduziert man die Exposition ohne Überengineering
Kurze Checkliste
- Standardbibliothek der Plattform-Laufzeit verwenden
- Vollständige Bezeichner intakt lassen
- Eindeutigkeit auf Speicherebene erzwingen
- Retry-Logik bei Duplicate-Insert-Fehlern hinzufügen
- UUIDs nicht als Geheimnisse oder Autorisierungs-Tokens verwenden
- Generator-Verhalten in Containern, Workern und wiederhergestellten Snapshots testen
Was zu überwachen ist
Die UUID-Kollisionsrate sollte nicht als normale Geschäftskennzahl behandelt werden, von der man erwartet, dass sie steigt. Sie sollte ein Anomaliesignal sein. Wenn Duplikate aufzutreten beginnen, Entropie, Deployment-Images, Zufalls-Seeding und benutzerdefinierten Transformationscode untersuchen, bevor man die Wahrscheinlichkeit beschuldigt.
Fazit
Zufällige UUIDs sind keine Magie. Sie sind ein sehr starkes Engineering-Werkzeug, dessen Sicherheit aus einem enormen Raum plus korrekter Implementierung kommt. Für die meisten Systeme ist die Kollisionsfrage mathematisch interessant, aber betrieblich nebensächlich. Für groß angelegte oder sensible Systeme ist der richtige Ansatz keine Angst. Es ist diszipliniertes Design: vertrauenswürdige Generierung, Datenbank-Constraints, Wiederholungsversuche und Observability.
Wenn das System mit Duplikaten angemessen umgeht, bleiben UUIDs eine der praktischsten Methoden zur Bezeichnervergabe ohne zentrale Koordination. Das ist die echte Antwort: Verwende sie zuversichtlich, aber niemals blind.
UUIDs sind darauf ausgelegt, für reale Systeme eindeutig genug zu sein – nicht absolut unwiederholbar. Dieser Unterschied ist wichtig. Teams hören oft, dass ein zufällig generierter Bezeichner "im Wesentlichen eindeutig" sei, und hören dann auf, über Fehlerfälle nachzudenken. In der Praxis lautet die eigentliche Frage nicht, ob Duplikate theoretisch unmöglich sind, sondern wann sie betrieblich relevant werden.
Eine Kollision tritt auf, wenn zwei separate Objekte denselben Bezeichner erhalten. Bei korrekt generierten zufälligen UUIDs ist dieses Ereignis außerordentlich selten. Dennoch bedeutet selten nicht gleich inexistent. Entwickler müssen die Mathematik dahinter, die Implementierungsfallen und den Unterschied zwischen einem statistischen Grenzfall und einem Produktionsfehler verstehen.