Qué significa realmente una colisión en producción
Una colisión de UUID no es un problema filosófico. Es un problema concreto de sistemas.
Cuando dos registros reciben el mismo identificador, generalmente ocurre uno de los siguientes:
- una inserción en base de datos falla por una restricción de unicidad
- un registro sobreescribe a otro
- una API devuelve el objeto equivocado
- un flujo de eventos vincula acciones no relacionadas
- los registros de log se vuelven más difíciles de confiar durante el análisis de incidentes
Por qué la matemática abstracta no cuenta toda la historia
El modelo teórico asume una fuente de aleatoriedad de alta calidad y un formato correcto. Los sistemas reales rompen esas suposiciones con más frecuencia de lo que la gente espera. La probabilidad de colisión de UUID en un generador bien implementado es pequeña, pero la mala entropía, la inicialización defectuosa, las instantáneas de VM copiadas o las bibliotecas caseras pueden hacer que los valores duplicados aparezcan mucho antes de lo que sugiere la fórmula.
La diferencia práctica entre «posible» y «relevante»
Para la mayoría de las aplicaciones web, herramientas internas y backends SaaS, la probabilidad es tan baja que otros fallos dominan. Los errores de disco, las condiciones de carrera, las migraciones incorrectas y la lógica de reintento deficiente son mucho más susceptibles de dañar la integridad de los datos. La matemática de UUID se vuelve importante a muy gran escala o en sistemas sensibles a la seguridad donde incluso un caso extremo debe modelarse.
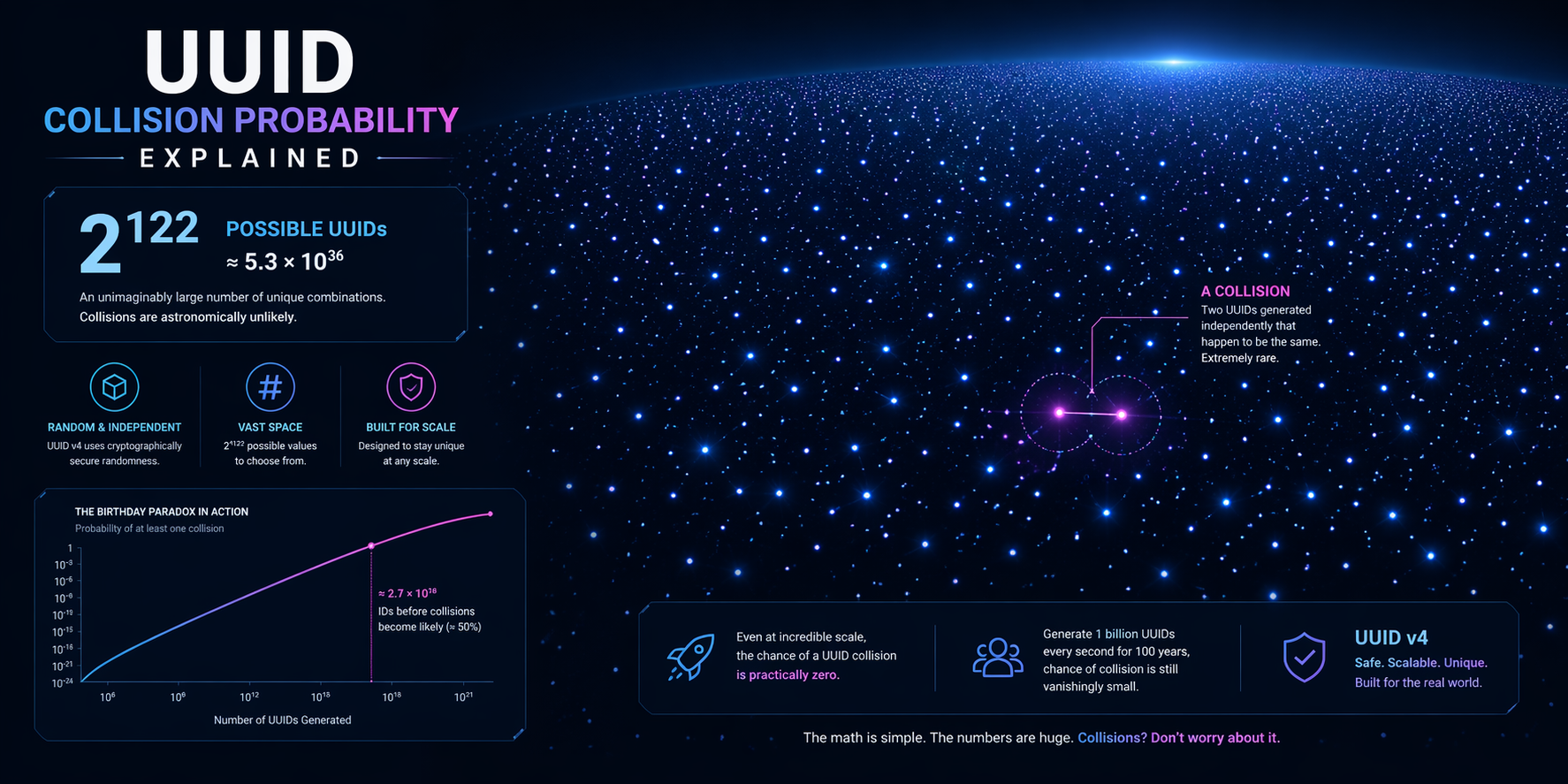
Cómo se estima la probabilidad
La intuición proviene de la paradoja del cumpleaños. No es necesario agotar todo el espacio de identificadores antes de que los duplicados sean posibles en principio. Solo se necesitan suficientes extracciones para que la superposición se vuelva estadísticamente notable.
La fórmula que los ingenieros realmente usan
Para un UUID aleatorio con ciento veintidós bits aleatorios, la probabilidad de colisión se aproxima frecuentemente como:
P ≈ n² / (2 × 2¹²²)
Donde:
- P es la probabilidad aproximada de al menos un duplicado
- n es el número de identificadores generados
Esta fórmula es útil porque muestra el comportamiento de escalado real: el riesgo crece con el cuadrado del tamaño de la muestra. Eso no hace que las colisiones sean comunes. Muestra por qué el crecimiento importa más de lo que muchos equipos asumen.
Leer la fórmula correctamente
La probabilidad de colisión de UUID sigue siendo insignificante para cargas de trabajo ordinarias, incluso cuando se crean millones o miles de millones de identificadores a lo largo del tiempo. La lección importante no es entrar en pánico. La lección es que la probabilidad es un objetivo móvil vinculado al volumen, la calidad del generador y el diseño del sistema.
Cuándo importan las probabilidades y cuándo no
La mayoría de los equipos hacen la pregunta equivocada. Preguntan si un UUID puede alguna vez repetirse. Una mejor pregunta es si la duplicación debe ser parte del modelo de fallos del sistema.
Verificación rápida de la realidad
|
Escenario |
Preocupación por colisión |
Razón principal |
|
App interna pequeña |
Mínima |
El volumen es bajo y las restricciones de base de datos capturan anomalías |
|
API pública con alto throughput de escritura |
Baja pero vale la pena modelar |
Gran volumen de identificadores durante largos períodos |
|
Sistema distribuido multiregión |
Preocupación operativa moderada |
La calidad del generador y la consistencia del entorno importan |
|
Token de seguridad mal usado como UUID |
Alta – error de diseño |
La predecibilidad y la semántica importan más que la duplicación |
Las probabilidades de colisión de UUID normalmente no son lo que rompe un sistema primero. Las suposiciones débiles en torno a las inserciones, los reintentos y el manejo de conflictos lo rompen primero.
Ejemplo: ruta de inserción en base de datos
Supongamos que un servicio de pedidos genera un identificador antes de escribir en el almacenamiento. Un diseño seguro hace esto:
- generar el identificador con una biblioteca de confianza
- imponer un índice único en la base de datos
- reintentar ante un fallo de clave duplicada
- registrar el evento para su investigación
Ese patrón trata las colisiones como improbables pero manejadas, que es exactamente la mentalidad correcta.
Fuentes reales de problemas con UUID más allá de la probabilidad pura
Los equipos a menudo culpan a las matemáticas cuando el problema real es la implementación.
Entropía débil
Los contenedores restaurados desde la misma imagen de máquina o entornos con poca aleatoriedad pueden crear patrones de salida repetidos. En ese caso, el riesgo de colisión de UUID ya no está impulsado principalmente por el espacio de identificadores. Está impulsado por una fuente de entrada defectuosa.
Uso incorrecto de bibliotecas
Un equipo puede truncar identificadores para URLs más bonitas, eliminar secciones o convertirlos a través de código personalizado con errores. El resultado puede seguir pareciendo un UUID pero contener mucha menos entropía de lo esperado.
Identificador equivocado para el trabajo
Un UUID determinístico basado en nombres puede producir intencionalmente el mismo valor para la misma entrada. Eso no es un error. Se convierte en un error solo cuando un equipo espera comportamiento aleatorio de un esquema determinístico.
Situaciones técnicas comunes
Ejemplo: mala estrategia de acortamiento
Un desarrollador toma solo la primera parte de un UUID para acortar los enlaces:
/full-id/abcfde...
/short-id/abcf
Eso cambia dramáticamente la superficie de colisión. El identificador puede seguir pareciendo técnico, pero sus garantías de unicidad ya no pertenecen a la misma clase.
Ejemplo: lógica de inserción segura
INSERT INTO files(id, path, owner)
VALUES (:generated_id, :path, :owner);
Esto es seguro solo cuando id tiene una restricción de unicidad y la aplicación sabe cómo reintentar.
Ejemplo: correlación de logs
Usar el mismo formato de identificador para el rastreo entre servicios está bien, pero el identificador no debe tener significado empresarial. Si alguna vez aparece un duplicado, la observabilidad debe revelarlo en lugar de ocultarlo.
La pregunta que los ingenieros siguen haciendo
La frase «puede colisionar un UUID» merece una respuesta directa: sí, en teoría, y a veces en la práctica. Pero con generación aleatoria de alta calidad, el evento es tan raro que los errores operativos dominan el peligro en el mundo real.
¿Alguna vez han aparecido duplicados?
La pregunta «¿ha habido alguna vez colisiones de UUID?» se hace a menudo como si refutara el modelo. No lo hace. Los duplicados reportados generalmente provienen de generadores defectuosos, entornos de baja entropía, truncamiento, errores de copiar y pegar o uso indebido de variantes determinísticas. La lección es simple: la mayoría de los «fallos de UUID» son fallos de ingeniería, no fallos del concepto subyacente.
Cómo reducir la exposición sin sobreingeniería
Usa una lista de verificación corta
- usar una biblioteca estándar del entorno de ejecución de la plataforma
- mantener los identificadores completos intactos
- imponer unicidad en la capa de almacenamiento
- añadir lógica de reintento ante errores de inserción duplicada
- evitar usar UUID como secretos o tokens de autorización
- probar el comportamiento del generador en contenedores, workers e instantáneas restauradas
Qué monitorear
La tasa de colisión de UUID no debe tratarse como una métrica empresarial normal que se espera que aumente. Debe ser una señal de anomalía. Si los duplicados comienzan a aparecer, investigar la entropía, las imágenes de despliegue, la inicialización aleatoria y cualquier código de transformación personalizado antes de culpar a la probabilidad.
Conclusión
Los UUID aleatorios no son magia. Son una herramienta de ingeniería muy sólida cuya seguridad proviene de un espacio enorme más una implementación correcta. Para la mayoría de los sistemas, la cuestión de la colisión es matemáticamente interesante pero operativamente menor. Para sistemas a gran escala o sensibles, el enfoque correcto no es el miedo. Es el diseño disciplinado: generación de confianza, restricciones de base de datos, reintentos y observabilidad.
Si el sistema maneja los duplicados con gracia, los UUID siguen siendo una de las formas más prácticas de asignar identificadores sin coordinación central. Esa es la respuesta real: úsalos con confianza, pero nunca a ciegas.