Blog
Artículos recientes
Descubra las últimas noticias, consejos y casos de uso de nuestro servicio.
Encontrará descripciones técnicas, datos interesantes y cómo usar nuestro servicio para aprovechar al máximo las herramientas que ofrecemos.
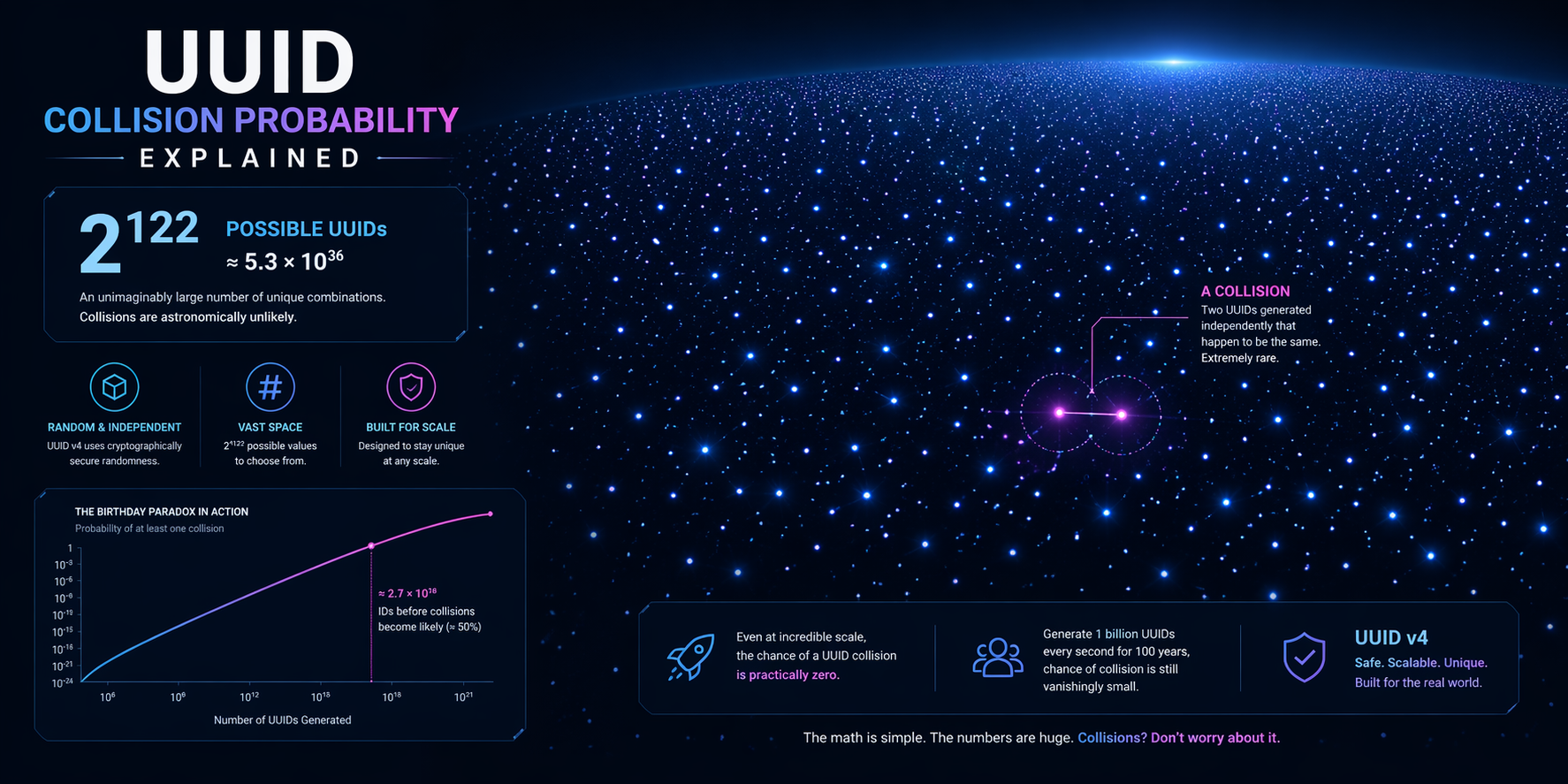
Los UUID están diseñados para ser suficientemente únicos en sistemas reales, no mágicamente imposibles de repetir. Esa distinción importa. Los equipos a menudo escuchan que un identificador generado aleatoriamente es «básicamente único» y luego dejan de pensar en los modos de fallo. En la práctica, la pregunta real no es si la duplicación es teóricamente imposible, sino cuándo se vuelve operativamente relevante.
Una colisión ocurre cuando dos objetos separados reciben el mismo identificador. Con UUID aleatorios correctamente generados, ese evento es extraordinariamente raro. Aun así, raro no es lo mismo que inexistente. Los ingenieros necesitan entender la matemática, las trampas de implementación y la diferencia entre un caso límite estadístico y un defecto de producción.
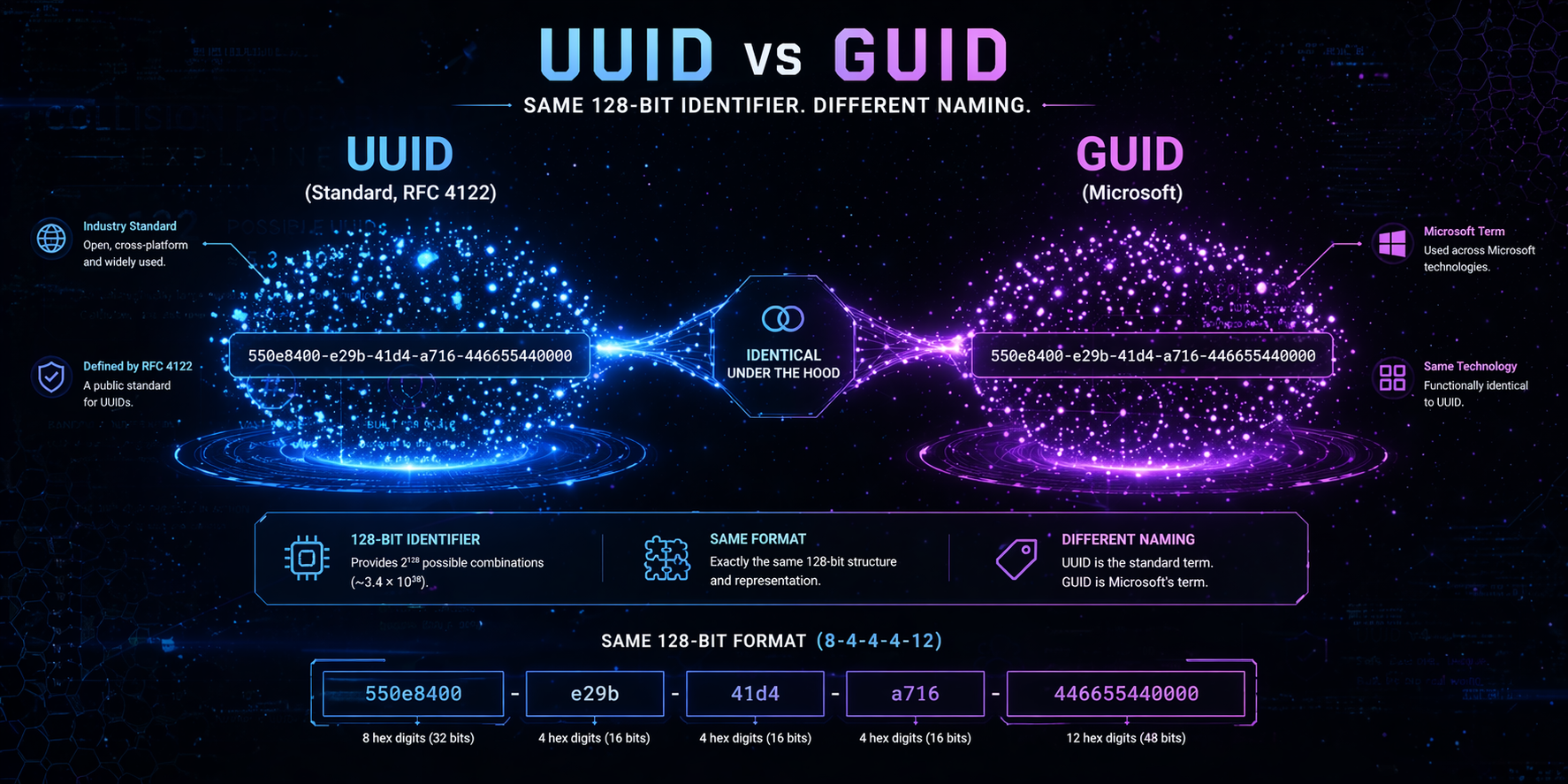
Los desarrolladores se encuentran con frecuencia con ambos términos en API, bases de datos, sistemas distribuidos y entornos Windows. A primera vista, parecen intercambiables, y en la mayoría de las implementaciones modernas, efectivamente lo son. Sin embargo, comprender su origen, la alineación de sus especificaciones y los detalles de su implementación ayuda a aclarar cuándo es importante la terminología y cuándo no.
Esta guía explica la estructura, las normas y las consideraciones prácticas sin repeticiones ni afirmaciones vagas, solo con distinciones técnicamente relevantes.

Los identificadores únicos universales (UUID) se utilizan ampliamente en sistemas distribuidos, bases de datos, API y microservicios para identificar entidades sin coordinación central. Los desarrolladores confían en ellos para evitar colisiones entre máquinas, regiones e incluso períodos de tiempo. Pero, ¿garantiza realmente un UUID la unicidad en la práctica, o se trata de una suposición exagerada?
Este artículo ofrece una explicación técnica, basada en ejemplos, de cómo funcionan los UUID, de dónde provienen sus garantías y en qué condiciones pueden aparecer, en teoría, problemas como la duplicación de UUID.

Los identificadores únicos son esenciales en las aplicaciones modernas. Ayudan a distinguir objetos, sesiones, registros de bases de datos y eventos de sistemas distribuidos sin colisiones. Un Identificador Universalmente Único (UUID) resuelve este problema generando identificadores con una probabilidad extremadamente baja de duplicación.
En esta guía, aprenderás formas prácticas de crear identificadores únicos en JavaScript utilizando APIs nativas del navegador, paquetes externos e implementaciones manuales. Los ejemplos son adecuados para entornos de frontend y backend.